"Simple" queries
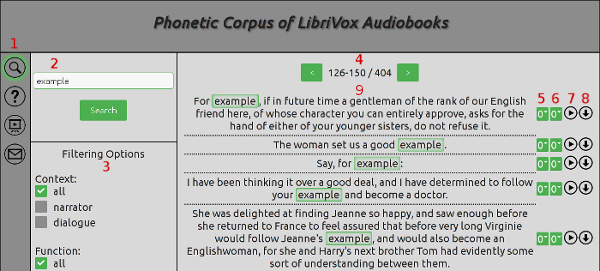
You can start using the corpus by typing a word or phrase in the search
bar. An example result is presented below.
1 – the navigation bar, which includes the search icon (searching may be
initiated from any other option chosen, but this icon will be activated once the search has
started), the help icon, the tutorial icon (you may watch a video tutorial offering a
comprehensive introduction to the functionality of the corpus) and the contact icon
2 – search bar
3 – filtering options (see Section 4.3 for details)
4 – pagination panel – "previous page" and "next page". Between these
icons, you can see the numbers referring to the currently displayed examples, and after the
forward slash "/" the number of all examples of the search term found in the corpus
5 – "left margin" - you may change the default value of 0 to any digit
between 1 and 5. This specifies the number of seconds added to the beginning of the audio
fragment
6 – "right margin" - you may change the default value of 0 to any digit
between 1 and 5. This specifies the number of seconds added to the end of the audio fragment
7 – "play button" - the button opens a new window in which the recording
is played. If a new window does not open, change the settings in your browser or disable your ad
blocking application.
8 - "download button" - the button initiates a download of the audio
file. If the download does not start automatically, change the settings in your browser or
disable your ad blocking application.
9 – results section – you may click any of the text units and a new
window will open with the details concerning the author, the novel, the reader, the context
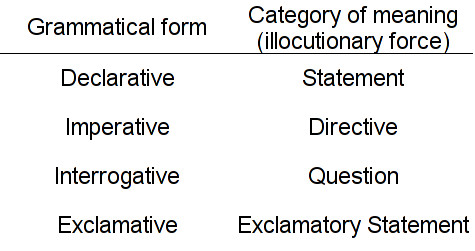
(narrator vs. dialogue), the function (statement/directive vs. question vs. exclamative
statement) and the location of the recording in the source audio file
Wildcards
At this moment, four wildcards are available:
? for "one character". For instance, the query "an?"
returns the following 9 types: and, any, ann, ant, ane, ana, anb, anz and ans.
The last three are hapaxes occurring only once in the entire corpus.
* for "one or more characters". For instance, the query
"an*" returns as many as 448 types including all the ones found in the previous example and
words such as another, anything or answered.
=c for "a consonant letter". The wildcard stands for
any letter which typically represents consonants in articulation. These letters are b, c, d,
f, g, h, j, k, l, m, n, p, q, r, s, t, w, v, x, z (although w may also be used
to represent diphthongs, as in how). For example, the query "an=c" returns the
following types: and, ann, ant, anb, anz and ans.
=v for "a vowel letter". The wildcard stands for any
letter which typically represents vowels in articulation. These letters are a, e, o, u, i,
y (y may also be used to represent the approximant /j/, as in yes). For
instance, the query "an=v" returns any, ane, ana.
The "consonant" and "vowel" letters do not represent individual
consonant and vowel phonemes because of the large distance between spelling and pronunciation in
modern English. These wildcards may be, however, quite useful in narrowing down searches.
All four wildcards may also be freely combined. For example, the query
"=c=v=v=c* ?o?" returns a large number of pairs of words. Each first word begins with a
consonant letter, followed by two vowel letters, followed by another consonant letter and
followed by 1 or more characters. Each second word begins with one character, followed by the
letter "o", followed by another single character. The results include phrases such as could
not, waiting for and heard you.